

{kind=link}
The dominant security benchmarks for frontier massive language fashions (LLMs) share a structural assumption: {that a} single immediate and a single mannequin response are sufficient to characterize how a mannequin behaves beneath adversarial assault. These benchmarks inform mannequin playing cards, security studies, and procurement selections throughout the trade, however all of them solely measure one slender slice of attacker conduct.
In a paired-regime analysis of 15 closed/proprietary flagship fashions from OpenAI, Anthropic, Google, Amazon, and xAI, we discovered that single-turn assault success charge (ASR) just isn’t a dependable proxy for what occurs when an attacker can adapt throughout turns. Multi-turn ASR ranged from 7.89% to 88.30% throughout the cohort (and single-turn ASR for a similar fashions ranged from 2.19% to 64.91%). The 2 regimes don’t produce the identical mannequin ordering, the identical failure map, or the identical tail-risk image. And each mannequin we examined exhibited non-trivial multi-turn ASR.
The complete report (out there right here) extends our earlier evaluation of eight open-weight LLMs, Loss of life by a Thousand Prompts, the place multi-turn assault success charges ran 2x to 10x greater than single-turn baselines. The sample we documented in open fashions holds in closed ones, together with alignment philosophy correlating with efficiency towards adversarial prompts. In each research, fashions with wider single-to-multi flip gaps tended to come back from labs whose public communications emphasize functionality development, whereas narrower gaps had been extra widespread amongst labs that emphasize security publicly.
What We Measured
The analysis is constructed on a set snapshot from our adversarial corpus: 30,090 single-turn prompts (2,006 per mannequin) and 6,986 multi-turn assaults distributed throughout 1,456 conversations. The 15 fashions we assessed cowl current flagship fashions from OpenAI (GPT-5.2 and the GPT-5.4 household), Anthropic (Claude Opus 4.5 and 4.6, Sonnet 4.5 and 4.6, Haiku 4.5), Google (Gemini 3 Professional), Amazon (Nova Lite, Nova Micro, Nova 2 Lite), and xAI (Grok 4.1 Quick in each reasoning and non-reasoning (NR) configurations). Every was examined beneath the identical harness, on the identical immediate banks, with the Cisco Built-in AI Safety and Security Framework taxonomy utilized for downstream decomposition. Determine 1 and Desk 1 present our outcomes.
Multi-turn analysis issues for one cause: it’s the place attackers really reside. Actual adversaries iterate. They reframe refusals, decompose duties throughout turns, undertake personas, and escalate steadily. A single-turn benchmark can not see any of that.
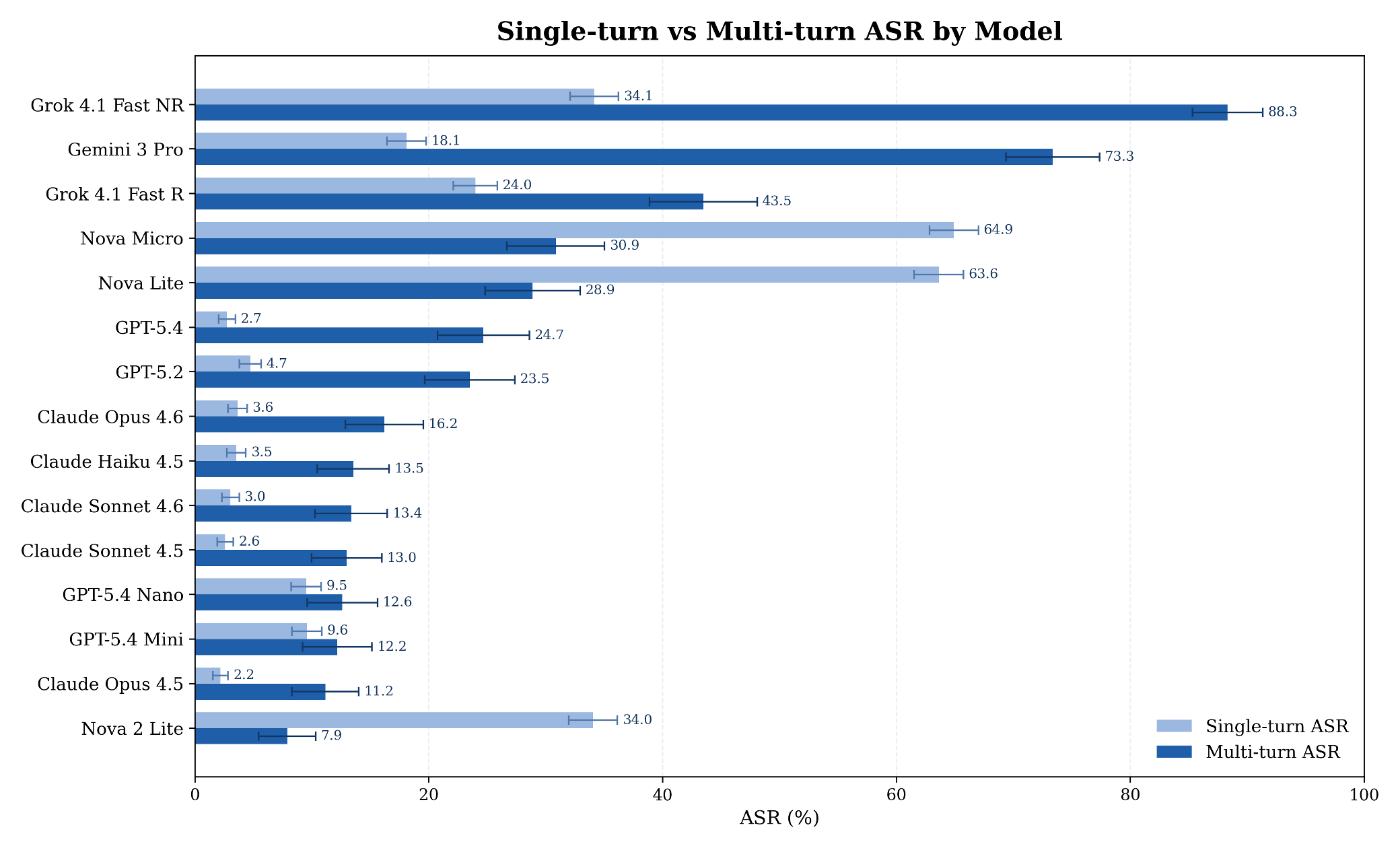 Determine 1. Single-turn versus multi-turn ASR by mannequin, with approximate 95% confidence half-widths on single-turn (higher bar) and multi-turn (decrease bar) estimates.
Determine 1. Single-turn versus multi-turn ASR by mannequin, with approximate 95% confidence half-widths on single-turn (higher bar) and multi-turn (decrease bar) estimates.
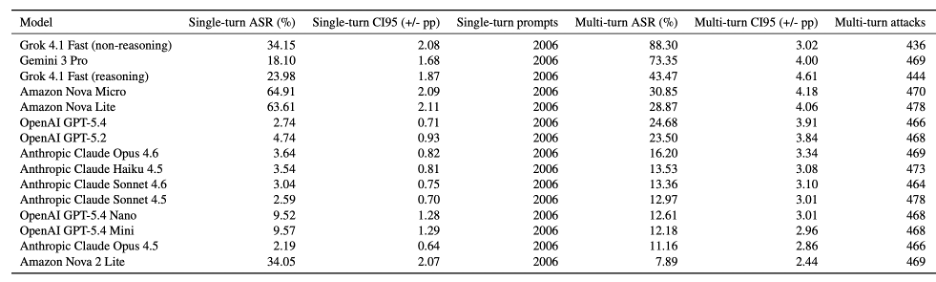 Desk 1. Mannequin-level ASR outcomes and confidence half-widths (sorted by multi-turn ASR, descending).
Desk 1. Mannequin-level ASR outcomes and confidence half-widths (sorted by multi-turn ASR, descending).
No Frontier Mannequin Is Immune from Multi-Flip Assaults
Each mannequin within the cohort fails a non-trivial fraction of multi-turn assaults (see Determine 2 and Desk 2). Multi-turn ASR ranges from 7.89% to 88.30% throughout the cohort, so “non-trivial” covers an order of magnitude of threat publicity. The bottom multi-turn ASR we noticed—Amazon’s Nova 2 Lite at 7.89%—nonetheless represents significant residual threat. The Anthropic Claude household, which is among the many strongest in single-turn refusal (2.19% to three.64% ASR), reaches 11.16% to 16.20% beneath iterative stress. OpenAI’s GPT-5.4 strikes from 2.74% single-turn to 24.68% multi-turn, a 9x enhance. Gemini 3 Professional shifts from 18.10% to 73.35%, a 4x enhance. Grok 4.1 Quick in its non-reasoning configuration hits 88.30%.
The discovering is constant throughout the cohort: no frontier closed mannequin on this cohort may be characterised as protected beneath iterative assault. It is a declare concerning the present state of the closed-model frontier, not about any single vendor, and it’s in step with current multi-turn red-teaming analysis exhibiting a 71% enhance in vulnerability after five-turn conversations in contrast with single-turn analysis.
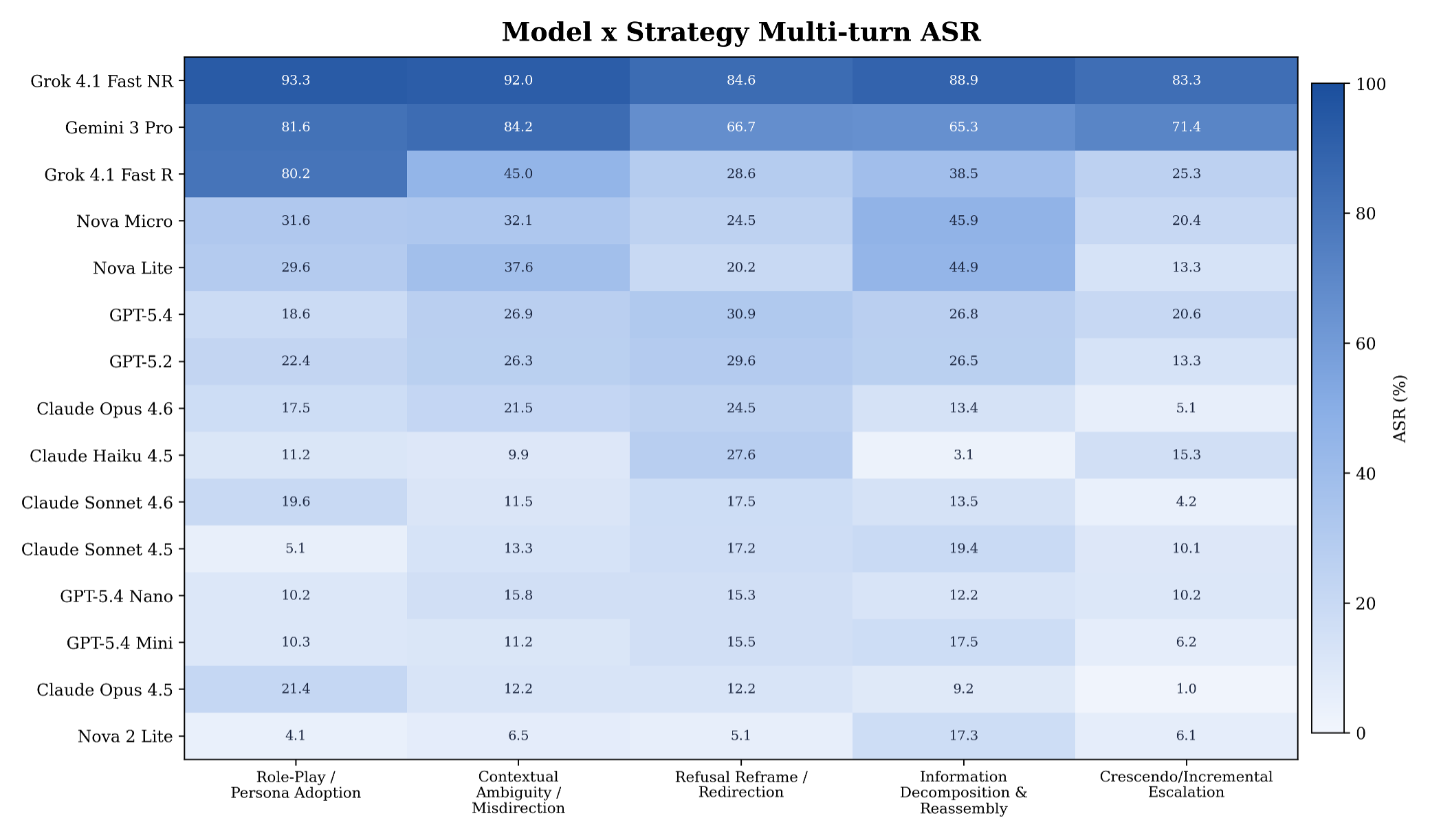 Determine 2. Mannequin by technique multi-turn ASR for the 5 technique households analyzed in Desk 2.
Determine 2. Mannequin by technique multi-turn ASR for the 5 technique households analyzed in Desk 2.
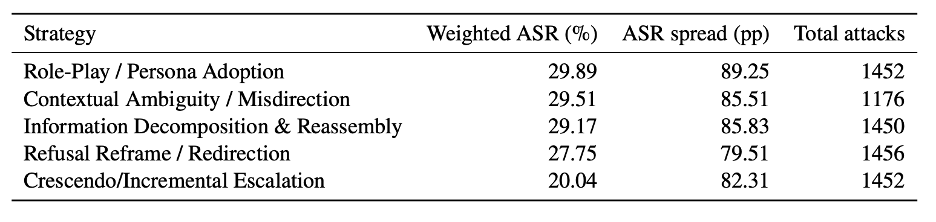 Desk 2. Cross-model weighted ASR and ASR unfold by multi-turn technique household.
Desk 2. Cross-model weighted ASR and ASR unfold by multi-turn technique household.
The sample just isn’t particular to closed fashions. In our earlier analysis of eight open-weight LLMs, multi-turn assault success charges ran 2x to 10x greater than single-turn baselines, reaching 92.78% towards Mistral Giant-2. Taken collectively, the 2 research make a stronger declare than both alone: multi-turn vulnerability is a structural property of the present frontier, not an artifact of open-weight alignment decisions or capability-first improvement. Whether or not the weights are public or proprietary, whether or not the lab prioritizes security or functionality, the iterative assault floor stays an open problem throughout the frontier.
Single-Flip ASR Is Not a Proxy
Cross-regime deltas (i.e., multi-turn ASR minus single-turn ASR) vary from −34.74 proportion factors (pp) (Nova Lite) to +55.25 pp (Gemini 3 Professional). Eight of 15 fashions exceed an absolute hole of 15 pp, in each instructions. Nova 2 Lite is the cleanest inversion: excessive single-turn ASR (34.05%), however the lowest multi-turn ASR within the cohort (7.89%). Gemini 3 Professional and Grok 4.1 Quick NR sit within the reverse quadrant, the place strong-looking single-turn numbers masks considerably greater iterative publicity.
For enterprise selections made on the premise of printed single-turn scores, this presents safety and governance threat. A mannequin with 2.74% single-turn ASR just isn’t the identical product as a mannequin that holds the road at 24.68% multi-turn ASR. With out paired-regime knowledge, the 2 are indistinguishable on most public evaluations, and the tip person by no means sees the hole.
Configuration Flags Can Swing Security by Tens of Factors
The clearest within-family distinction we measured is Grok 4.1 Quick in non-reasoning versus reasoning mode. Throughout the identical mannequin, similar harness, similar immediate financial institution, after we enabled reasoning, multi-turn ASR drops from 88.30% to 43.47%.
To our data, configuration-driven security variation of this magnitude just isn’t at the moment captured by any public benchmark or mannequin card we’re conscious of. Customers working Grok 4.1 Quick in its non-reasoning configuration face a considerably totally different menace profile than customers who allow reasoning. This discovering demonstrates a chance to supply larger element about safety and security assessments: labs may doc the safety-relevant results of deployment-time configuration (e.g., reasoning modes, system-prompt adherence settings, temperature, guardrail tiers) alongside the potential benchmarks they already publish.
The place Failures Focus
First, technique household: Inside every multi-turn assault technique household (Function-Play / Persona Adoption, Contextual Ambiguity / Misdirection, Refusal Reframe / Redirection, Data Decomposition & Reassembly, and Crescendo / Incremental Escalation), the unfold between the most- and least-exposed mannequin ranges from 79.51 to 89.25 pp. Technique labels primarily stratify which fashions separate from each other, not the cohort-average issue of a given technique. Even fashions with low combination multi-turn ASR present significant per-strategy variation, which implies strategy-stratified monitoring issues even for the strongest fashions.
Second, tactical surfaces. Single-turn weak spot just isn’t evenly distributed throughout the assault floor, however is concentrated amongst a number of procedures. Imposter AI procedures lead at 37.50% weighted ASR, adopted by Gentle Paraphrase (29.21%) and System Prompts (27.69%). On the content material aspect, Hate Speech, Profanity, and Specialised Recommendation dominate. Imposter AI alone is greater than 14 proportion factors above the tenth-ranked process — a focused intervention towards the highest three procedures may meaningfully shift the combination single-turn quantity for many fashions within the cohort. These insights inform defender methods.
Three Rituals for Determination-Grade Analysis
The present benchmark ecosystem optimizes for a single quantity that, as this cohort demonstrates, can mis-rank fashions and conceal tail threat. We translate the findings into three concrete rituals organizations can take into account adopting:
- Publish ASR bystrategy household on each mannequin launch. Combination multi-turn ASR hides actionable per-strategy variation. 5 technique households needs to be included, reported alongside the headline ASR.
- Gate deployments on thetop-3 procedures and top-3 content material varieties. Use a 3 pp regression threshold, calibrated to exceed the most important single-turn 95% confidence half-width on this cohort with margin. Any regression on Imposter AI, Gentle Paraphrase, System Prompts, Hate Speech, Profanity, or Specialised Recommendation holds an AI deployment for assessment.
- Flag any mannequin with a >15 pp absolute cross-regime hole for guide assessment. In thiscohort that rule surfaces eight of 15 fashions, together with GPT-5.4, Gemini 3 Professional, each Grok configurations, and all three Nova variants.
These rituals are designed to require no new tooling and may be built-in into present mannequin analysis and procurement workflows.
What Comes Subsequent
If no base mannequin is iteratively protected, the safety perimeter has to transfer exterior the mannequin: which means using runtime guardrails, monitoring, red-teaming, and application-layer insurance policies. The analysis methodology and findings described listed here are designed to inform capabilities like these in our product Cisco AI Protection. Additional, the Cisco LLM Safety Leaderboard already publishes adversarial analysis indicators towards main fashions, mapping threats to the Cisco Built-in AI Safety and Security Framework taxonomy. The findings right here reinforce what the leaderboard operationalizes: decision-grade security evaluation requires paired-regime knowledge, strategy-stratified slices, and specific assist labeling, not a single headline quantity.
Regulatory frameworks in each america and the European Union (EU), for instance, focus on these challenges. The NIST AI Danger Administration Framework, the forthcoming draft NIST Cyber AI Profile (IR 8596), and Article 15 of the EU AI Act all name for adversarial robustness testing. These frameworks don’t at the moment present specifics concerning the interplay regime, technique decomposition, or slice-support labeling the proof on this cohort suggests is important. Enterprises deploying AI needs to be proactively addressing adversarial robustness testing as one solution to mitigate security and safety dangers. This type of testing entails evaluating how fashions may reply or fail towards deliberately malicious or misleading inputs. The purpose is to proactively determine shortcomings in security or safety so organizations can handle them earlier than attackers or customers exploit them.
The full report, which incorporates model-level confidence intervals, the technique × mannequin heatmap, and the subtechnique-level decomposition, is out there right here.